
 (English below) Het Rekenen bij de Data project van Deltares en Rijkswaterstaat is succesvol afgerond! Het afgelopen jaar werkten we in DigiShape verband aan een project waarbij werd onderzocht hoe adviesbureaus en kennisinstellingen grote datasets kunnen analyseren, zonder dat deze data extern toegankelijk moeten worden gemaakt. Een manier om dit te doen, is het om te keren: je brengt een algoritme naar de data toe en deelt alleen de uitkomsten met de vraagsteller.
(English below) Het Rekenen bij de Data project van Deltares en Rijkswaterstaat is succesvol afgerond! Het afgelopen jaar werkten we in DigiShape verband aan een project waarbij werd onderzocht hoe adviesbureaus en kennisinstellingen grote datasets kunnen analyseren, zonder dat deze data extern toegankelijk moeten worden gemaakt. Een manier om dit te doen, is het om te keren: je brengt een algoritme naar de data toe en deelt alleen de uitkomsten met de vraagsteller.
In een testomgeving hebben we met succes dit rekenen bij de data mogelijk gemaakt, maar toch hebben we ervoor gekozen om deze nieuwe methode nog niet in productie te nemen. Fedor Baart van Deltares: “De belangrijkste reden hiervoor is dat het op dit moment gemakkelijker is om een persoon te vertrouwen dan een algoritme. We hebben al veel procedures om mensen ‘die van buiten komen’ te vertrouwen (overeenkomsten, gastmedewerkers), maar hoe vertrouw je een algoritme op je server? Daarvoor blijkt het nu nog te vroeg te zijn, maar we hebben wel een aantal inzichten en een referentie architectuur opgesteld, die we met de community willen delen.”
Aspecten die bij het vertrouwen van algoritmen komen kijken:
- Begrijpelijkheid: Is het algoritme begrijpelijk? Kunnen we de beslissingen die het neemt uitleggen aan gebruikers? Hiervoor gebruiken we een code review proces in github. Daarbij wordt gelet op documentatie, structuur en testen.
- Leesbaarheid: Is de code achter het algoritme goed gedocumenteerd en gemakkelijk te lezen? Hiervoor gebruiken we code standaard (in dit project black, isort en code quality checks zoals sonarcube).
- Verklaarbaarheid: Kunnen we de redenering achter de uitkomsten van het algoritme begrijpen? Dit is een actief onderwerp van onderzoek in de explainable AI.
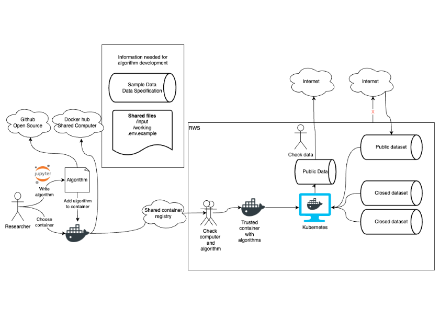
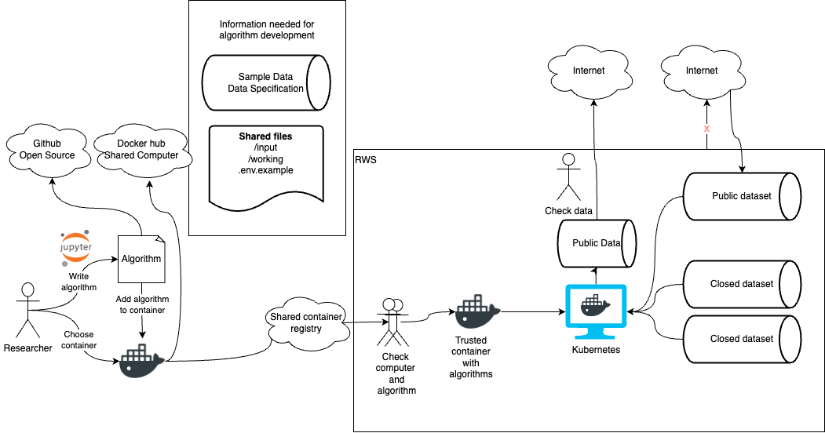
Referentie architectuur
Als resultaat van dit project kunnen we onderstaande referentiearchitectuur delen. Deze kan gebruikt worden om, met eenvoudige bestaande open source componenten, rekenen bij de data mogelijk te maken.
Fedor: “Hoewel het misschien te vroeg was voor dit idee, is het van essentieel belang om in een vroeg stadium dit soort experimenten uit te voeren. Het is de enige manier om te ontdekken of iets werkt, en zelfs als het niet direct slaagt, geeft het ons waardevolle inzichten die ons helpen bij toekomstige pogingen. En: we kunnen het later altijd nog een keer proberen.”
Meer informatie
Dit e-mailadres wordt beveiligd tegen spambots. JavaScript dient ingeschakeld te zijn om het te bekijken.
ENGLISH (translated with DeepL)
The Calculate by Data project of Deltares and Rijkswaterstaat has been successfully completed! Last year, we worked in DigiShape on a project that explored how consulting firms and knowledge institutions can analyse large datasets without having to make the data externally accessible. One way to do this is to turn it around: you bring an algorithm to the data and only share the results with the questioner.
In a test environment, we have successfully enabled this computation with the data, yet we have chosen not to put this new method into production yet. Fedor Baart of Deltares: "The main reason for this is that it is currently easier to trust a person than an algorithm. We already have many procedures to trust people 'coming from outside' (agreements, guest workers), but how do you trust an algorithm on your server? It appears to be too early for that now, but we have established some insights and a reference architecture that we want to share with the community."
Aspects involved in trusting algorithms:
- Understandability: Is the algorithm understandable? Can we explain the decisions it makes to users? For this, we use a code review process in github. This looks at documentation, structure and testing.
- Readability: Is the code behind the algorithm well documented and easy to read? For this, we use code standards (in this project black, isort and code quality checks such as sonarcube).
- Explainability: Can we understand the reasoning behind the algorithm's outcomes? This is an active topic of research in explainable AI.
Reference architecture
As a result of this project, we can share the reference architecture above. This can be used to enable, with simple existing open source components, computation at the data.
Fedor: "Although it may have been too early for this idea, it is essential to carry out these kinds of experiments at an early stage. It's the only way to find out if something works, and even if it doesn't succeed immediately, it gives us valuable insights that help us in future attempts. And: we can always try it again later."
More information
Dit e-mailadres wordt beveiligd tegen spambots. JavaScript dient ingeschakeld te zijn om het te bekijken.
